
AlbedoBase XL - V1.3
by ModelsLabv1.3
In order to illustrate the quality associated with the model's randomness, I standardized the seed value at '9' for all showcase images intended for sampling and proceeded with their immediate generation.
Especially with this version, due to the significant impact of negative prompts, leaving the negative prompt field empty is likely to produce the best quality.
The spec grid(438.7 MB): download
As you can see, as the number of Steps increases, it becomes available for all samplers, and the quality also improves.
Due to the effect of the LoRA I developed and merged, as described below, using sentence-form prompts rather than tag (a list of words) prompts is directly related to improving quality.
I merged 45 checkpoints and 7 LoRAs. After that, I merged AlbedoBase v0.4 and v0.3 in order, less than 0~5%, to reawaken the diluted merged models that had become outdated.
Among the 7 LoRAs, one is created by me. It involves analyzing and annotating captions for a total of 174 high-quality pictorial photos using GPT4-V. Merging this LoRA resulted in astonishingly clear images and an impressively excellent understanding of prompts.
My self-created LoRAs are exclusively available for purchase to my Ko-fi supporters at the Creative level or higher. I plan to release more and more updates in the future. The prices range from $10 to $50.
albedobase-xl-v1-3Input
Per image generation will cost 0.0047$
For premium plan image generation will cost 0.00$ i.e Free.
Output
Unknown content type
Related Models
Discover similar models you might be interested in
















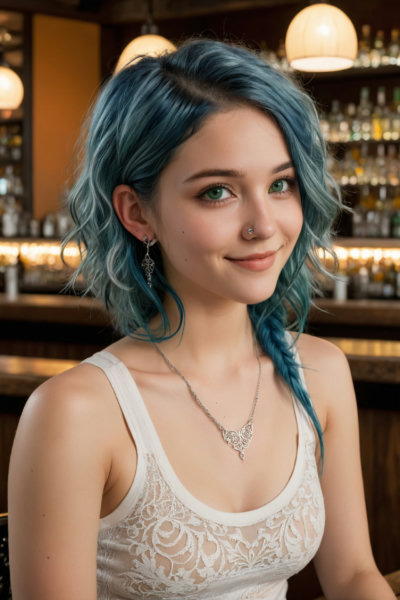

About AlbedoBase XL - V1.3
v1.3In order to illustrate the quality associated with the model's randomness, I standardized the seed value at '9' for all showcase images intended for sampling and proceeded with their immediate generation.Especially with this version, due to the significant impact of negative prompts, leaving the negative prompt field empty is likely to produce the best quality.The spec grid(438.7 MB): downloadAs you can see, as the number of Steps increases, it becomes available for all samplers, and the qua
Technical Specifications
- Model ID
- albedobase-xl-v1-3
- Provider
- Modelslab
- Task
- AI Generation
- Price
- $0.0047 per API call
- Added
- May 22, 2025
Quick Start
Integrate AlbedoBase XL - V1.3 into your application with a single API call. Get your API key from the pricing page to get started.
import requestsimport jsonurl = "https://modelslab.com/api/v6/images/text2img"headers = {"Content-Type": "application/json"}data = {"model_id": "albedobase-xl-v1-3","prompt": "your prompt here","key": "YOUR_API_KEY"}try:response = requests.post(url, headers=headers, json=data)response.raise_for_status() # Raises an HTTPError for bad responses (4XX or 5XX)result = response.json()print("API Response:")print(json.dumps(result, indent=2))except requests.exceptions.HTTPError as http_err:print(f"HTTP error occurred: {http_err} - {response.text}")except Exception as err:print(f"Other error occurred: {err}")
Pricing
AlbedoBase XL - V1.3 API costs $0.0047 per API call. Pay only for what you use with no minimum commitments. View pricing plans
AlbedoBase XL - V1.3 FAQ
v1.3In order to illustrate the quality associated with the model's randomness, I standardized the seed value at '9' for all showcase images intended for sampling and proceeded with their immediate generation.Especially with this version, due to the significant impact of negative prompts, leaving the
You can integrate AlbedoBase XL - V1.3 into your application with a single API call. Sign up on ModelsLab to get your API key, then use the model ID "albedobase-xl-v1-3" in your API requests. We provide SDKs for Python, JavaScript, and cURL examples in the API documentation.
AlbedoBase XL - V1.3 costs $0.0047 per API call. ModelsLab plans start at $21/month (Basic), and the $149/month Open Source plan includes unlimited generation on open-source models.
The model ID for AlbedoBase XL - V1.3 is "albedobase-xl-v1-3". Use this ID in your API requests to specify this model.
No — ModelsLab is subscription-based, with plans from $21/month (Basic, 3,250 API calls). The $149/month Open Source plan includes unlimited generation across open-source models.